 切换行业
切换行业

「用大量的机组正常运行数据训练一个模型,然后用这个模型去对机组的运行状况作诊断」。这样的提法只能说看上去很美,因为建立一个模型并不是一个非常容易做到的事情。原因有二:
其一、数据标记是个严肃的事情。所谓「正常运行数据」并不是那么容易获得,机组没有停机,没有故障,没有报警并不表明它就运行在「正常」状况下;所以,「正常数据」不那么容易得到,至少很难有好的手段保证数据的「纯度」。
其二,「模型」的结构和参数可以有很多选择,到底改如何选择,如何调参数,目前并没有有效的数据和手段去支撑。
在一些应用领域,训练得到一个模型,要做大量的交叉验证,才能保证模型结构和参数的有效性。而在我们这个领域,如果没有设备厂家精细而有专业的配合,这几乎是不可能的。
所以,「用大量的运行数据训练一个模型」只是一厢情愿的想法,并不是绝对做不到,而是要达到目的的路径很长,成本很高。
所以,要转变下思考方向。不要企图去训练一个模型,我们还有另外一招:异常检测,英文词源是 Abnormal detection。
异常检测是一种无监督机器学习算法,也就是说它不需要用标记过的数据作模型训练。它的原理并不难理解,我们看个图:
这是一个航空发动机的例子,坐标 x1 是设备温度,坐标 x2 是设备振动幅度。图中的两个绿色点,一个被标记成正常,一个被标记成不正常,从直观上很容易理解。并不需要一个模型来告诉我们一个正常与不正常,我们只需要根据得到数据的分布关系就可以做出一个判断。
这样的方法的基本原理就是用设备的实际运行数据估计一个概率密度函数,然后用这个概率密度函数去计算每一个点的概率,那些概率越小的点,是异常点的概率越大。
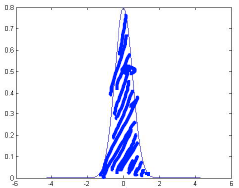
更具体地讲,异常检测算法的数学原理就是高斯分布。关于高斯分布的数学原理,我就不赘述了,下面的两个图就是两种不同参数的高斯分布。
有了一定的数据量,就可以预估出高斯分布的密度函数,从而可以计算各个数据点的概率值,根据这个概率就可以判断异常的可能性大小。
也就是说,我们只要有数据就可以做这样的计算,我们不需要对数据代表的设备状态做标记,并且我们也不需要调参数,也不需要考虑模型结构。
所以,异常检测的实际操作性很强,我们需要做以下两件事:
其一,我们需要根据设备的分析目标选取数据,比如分析齿轮箱该选哪些数据,分析变桨系统需要哪些数据,分析整个机组的运行情况需要哪些数据。
其二,选取尽可能覆盖可能的工况的数据。
其三,概率密度预估,确定概率阈值。





 正在加载...
正在加载...


