

风能是一种清洁、可再生的能源,正迅速成为可持续发展和能源战略的重要组成部分[1,2]。但是风力发电过程中随机变化的风速风向使得风电功率具有波动性、间歇性和随机性等特征,对电力系统运行的稳定性和可靠性造成不利影响[3-5]。
消除这些不利影响的一种重要手段就是通过风电机组运行数据的挖掘提高风力发电的可预见性。通过实测风速和功率得到的风功率曲线可用于评估风电机组的性能和运行状况,对判断风机故障有重要价值,同时时序功率数据也是研究风电功率预测以及评估风功率对电网影响的基础[6]。因此,准确获得风电机组实际运行的风速和功率数据,能够为风电场的经济安全运行和优化控制策略提供根本的数据支撑。
但是在风电场运行过程中,由于机组停机、减载、通信噪声和设备故障等因素,会产生大量异常数据。目前风电机组运行数据的收集、管理、分析和挖掘方法仍存在诸多不足,不能准确辨识所采集数据的质量差异,进而有效支撑粗糙数据的正确筛选和合理化优化,造成数据质量得不到保障[7]。
如果这些数据不经处理直接使用,得到的风力发电统计特性发生畸变,会影响风电机组的运行状态和运行特性的分析结果。为了提高数据质量,数据清洗已成为数据挖掘过程中不可或缺的环节[8]。
风电机组异常运行数据的识别与清洗是当前的研究热点,已开展大量工作并取得了诸多研究成果,其中风电机组风功率曲线数据清洗的代表性成果有:文献[9]采用的四分位法是一种常用的异常数据识别方法,但是当异常数据所占的比重较大时,四分位法识别异常数据的效果变差;文献[10]采用四分位法与k-means联合算法剔除异常数据,但由于k-means算法属于分类算法,可能会导致正常数据的误删,且k值的确定比较复杂,对数据处理结果影响较大;
文献[11]采用组内最优方差算法实现了功率曲线下方的堆积型异常数据的有效识别效果,但该算法将每个风速区间内最大的功率默认为风机满发功率,无法识别功率曲线上方的异常数据;文献[12]通过建立风功率曲线的非线性模型实现异常数据的识别,该方法需要大量的正常数据作为样本,否则训练误差会较大,另外数据处理速度较慢;
文献[13]在假设风功率的概率密度函数服从正态分布的基础上,提出了基于3 法则的异常数据清洗方法,与实际风电运行数据中由于堆积型异常数据的存在风功率的概率密度函数往往呈双峰或多峰分布不符,其普适性及异常数据识别效果不好;
文献[14,15]采用基于密度的局部离群因子(Local Outlier Factor, LOF)算法,把具有足够高密度的区域划分为簇,实现了分散型异常数据的有效识别,但不能有效识别密度较高的堆积型异常数据。
综上所述,当前风电机组风速-功率运行数据清洗方法从原理上可分为三类:第一类方法是根据数据点的密度或距离来判断该点是否为异常点,但该类方法对分布密集的堆积型异常数据识别效果有限;第二类方法是建立风功率曲线的数学模型,但此类方法需要大量正常数据作为样本,且普适性较差;第三类方法是根据异常数据的位置分布特征识别异常数据,该类方法的依据是异常数据点位于风功率曲线正常出力特性范围之外,理论上可实现多类型异常数据的清洗,而且不需要数据样本训练,通用性强,后续应用值得期待,但现有研究成果对大量堆积型异常数据的识别与清洗效果有待提高。
另外,全面研究分析风速-功率曲线异常数据的空间分布位置和形态对改进该类方法识别清洗效果具有实际的指导意义,相关研究开展得尚不系统。鉴于此,本文首先分析了风电机组风速-功率异常数据的分布特征及分类,然后根据异常数据分布特征提出一种基于变点分组与四分位法的联合数据清洗算法和流程,最后从提出算法的有效性、流程的合理性及清洗效率等维度进行了分析验证。
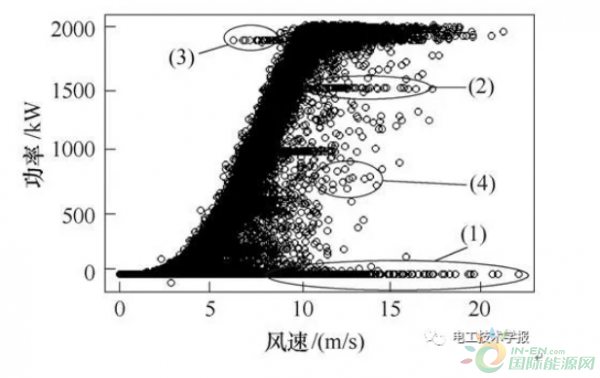
图1 风功率曲线异常数据分布特征示意
结论
风电机组风速-功率异常数据会对风电数据挖掘带来负面影响。本文总结了风电机组风速-功率异常数据的分布特征,提出并建立了变点分组-四分位法数据清洗方法及流程。实例验证表明,所提的数据清洗方法及流程能够有效识别异常数据,效率较高,且不依赖于正常数据集进行训练,通用性较好。








